Funktionen des Schema-Editors
Der Schema-Editor bietet Funktionen zum Einbetten semantischer Metadateninformationen in das OpenAPI/JSON-Schema der API. Zwei Schlüsselfunktionen sind die Möglichkeit, den SPARQL-Endpunkt zu konfigurieren, der dann für die Abfrage von RDF-Ressourcen nützlich ist, und die Aktivierung der automatischen Vervollständigung für Terme und Klassen.
Konfigurieren des SPARQL-Endpunkts
Der Schema-Editor fragt externe Ressourcen mit SPARQL ab, einer Sprache, die für die Abfrage von RDF-Datensätzen entwickelt wurde.
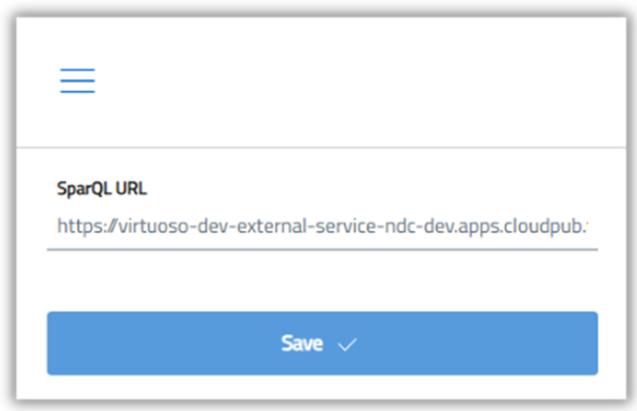
Standardmäßig verwendet der Editor den SPARQL-Endpunkt des Katalogs. Sie können es jedoch ändern, um eine Verbindung zu einem anderen SPARQL-Server herzustellen, was beispielsweise bei der Arbeit mit benutzerdefinierten Datensätzen oder verteilten RDF-Infrastrukturen nützlich ist. Klicken Sie dazu auf das Burger-Symbol (≡) in der oberen linken Ecke der Benutzeroberfläche.
So ändern Sie den SPARQL-Endpunkt:
- Klicken Sie auf das Burger-Symbol (≡) in der oberen linken Ecke der Benutzeroberfläche.
- Wählen Sie im Seitenmenü den Eintrag Konfiguration aus.
- Geben Sie die URL des neuen SPARQL-Endpunkts in das dafür vorgesehene Feld ein.
Sobald die Konfiguration gespeichert ist, verwendet der Editor den neuen Endpunkt für alle Abfragen.
Automatische Vervollständigung verwenden
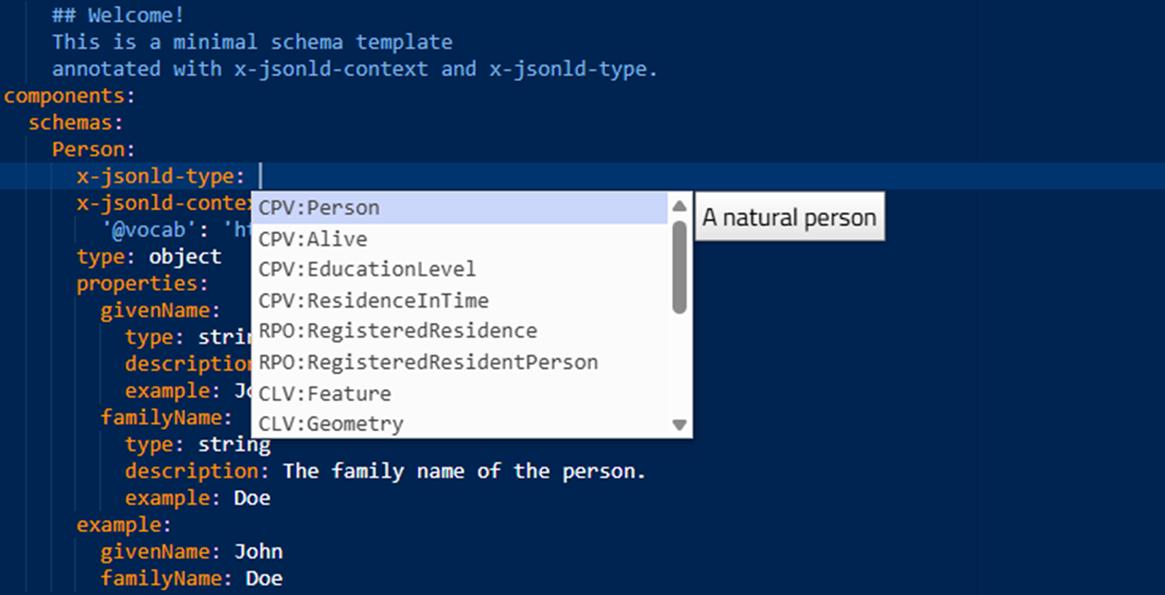
Der Schema-Editor kann beim Tippen automatisch Begriffe und Klassen vorschlagen, basierend auf einem ausgewählten Satz von Vokabeln, die im schema.gov.it-Katalog verfügbar sind. So verwenden Sie die Selbstvervollständigung:
- Drücken der Kombination STRG + RAUM Es wird eine Dropdown-Menü mit einer Liste kompatibler Vorschläge;
- Durch Eingabe von Text wird die Liste dynamisch gefiltert;
- Pressen SENDEN auf Vorschlag wird der Editor automatisch das Feld mit demUri korrekt für die ausgewählte Klasse oder Eigenschaft.
Diese Funktionalität vereinfacht das Einfügen korrekter Referenzen erheblich und reduziert das Risiko ungültiger Syntax- oder URI-Fehler.
Navigation im Bereich Datenmodelle
Der Abschnitt Datenmodelle des Schema-Editors bietet eine strukturierte Übersicht über alle im Schema definierten RDF-Klassen. Es soll die Analyse der Eigenschaften erleichtern, die mit jeder Klasse und ihren semantischen Verbindungen verbunden sind.
Hauptfunktionen
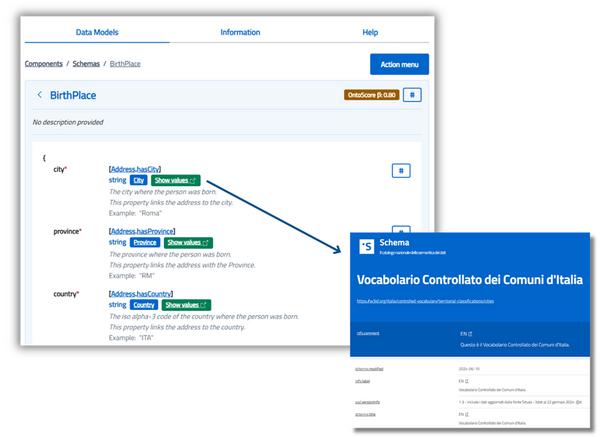
- Automatische Anzeige von RDF-Klassen Der Editor ruft automatisch alle RDF-Klassen im Schema ab. Für jede Klasse werden die folgenden aufgelistet:
• die zugehörigen Eigenschaften;• Semantische Verknüpfungen, die sich aus Mappings mit Referenzklassen ergeben.
- Details zu jeder Eigenschaft Jede angezeigte Eigenschaft wird mit nützlichen Informationen zum Verständnis des Modells angereichert:
• Syntaktischer Typ (z.B. String, Zahl, Objekt);
• Semantischer Typ (assoziierte RDF-URI);
• Textliche Beschreibung;
• Anwendungsbeispiel, generiert nach Schemadefinitionen. - OntoScore-Berechnung – Semantischer Abdeckungsindikator Der Schema-Editor berechnet einen Indikator namens OntoScore, der den semantischen Mapping-Level des Schemas misst. Es ist definiert als das Verhältnis der Gesamtzahl der im JSON-Schema vorhandenen Eigenschaften zur Anzahl der Eigenschaften, die mit einem rdf:Property korrekt zugeordnet wurden. Dieser Score hilft zu beurteilen, wie semantisch das Schema mit RDF-Vokabularen ausgerichtet ist.
- Wenn eine Klasse mit einem kontrollierten Vokabular verknüpft ist, wird die Schaltfläche "Werte anzeigen" angezeigt. Wenn Sie darauf klicken, gelangen Sie direkt zum entsprechenden Abschnitt auf schema.gov.it, in dem alle zulässigen Werte für diese Eigenschaft aufgeführt sind.
Navigation von Analysetools
Dieser Abschnitt des Schema Editors enthält eine Reihe von Tools, die für die semantische Analyse, RDF-Visualisierung und JSON-LD-Kompatibilitätsvalidierung entwickelt wurden. Durch verschiedene interaktive Panels ist es möglich, die Struktur des Schemas zu erforschen, seine semantische Bedeutung zu verstehen und sein Verhalten in realen RDF-Kontexten zu überprüfen.
JSON-LD Playground verwenden
Mit dem Schema Editor können Sie ein Beispiel automatisch generieren und im externen JSON-LD Playground Tool öffnen. Mit dieser Funktion können Sie:
- Anzeige des vom Schema erzeugten JSON-Eingangs;
- Untersuchen Sie den JSON-LD-Kontext und seinen @type;
- Erhalten Sie eine RDF-Serialisierung in den Formaten Turtle, RDF/XML und N-Quads.
Dieses Tool ist nützlich, um die Richtigkeit der semantischen Darstellung von Daten zu testen.
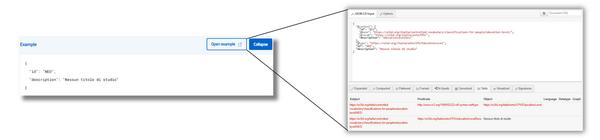
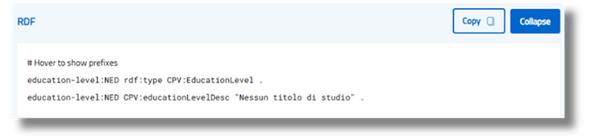
Verwenden Sie RDF-Tripletts
Der RDF-Abschnitt zeigt die Schemainformationen in RDF-Trilets (im Formularsubjekt – Prädikat – Objekt) und bietet eine klare Darstellung der semantischen Struktur. Mit dieser Ansicht können Sie:
- Erforschen Sie visuell die semantischen Beziehungen zwischen Entitäten und Eigenschaften;
- Überprüfen Sie die Konsistenz des Modells mit dem RDF-Diagramm;
- Verstehen, wie Schemainstanzen in semantischen Systemen interpretiert werden
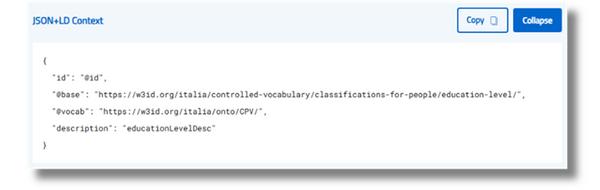
JSON-LD-Kontext verwenden
Der Inhalt des Abschnitts JSON-LD-Kontext wird automatisch aus den Metadaten (x-jsonld-Typ und x-jsonld-Kontext) im Schema generiert. Zu den Hauptmerkmalen gehören:
- respektiert die Hierarchie des Systems unter Beibehaltung eines kohärenten Kontexts;
- Anwenden der automatischen Kontextvererbung auf untergeordnete Ebenen, sofern nicht anders angegeben;
- Erzeugt eine Ausgabe, die den JSON-LD-Spezifikationen entspricht und bereit ist, in Systeme integriert zu werden, die auf RDF-Ontologien basieren.
Dieses Panel ist der Schlüssel zur Gewährleistung einer effektiven semantischen Integration und interoperablen Veröffentlichung von Daten.
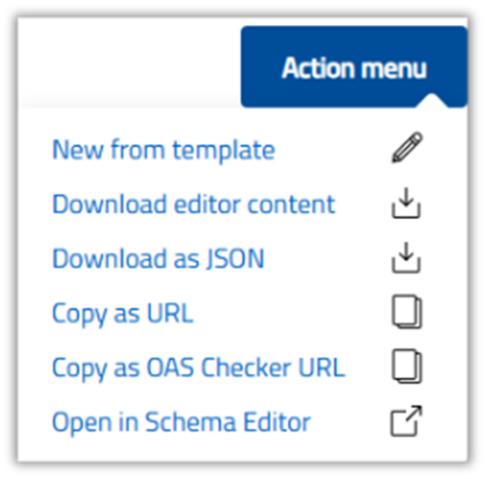
Aktionsmenü verwenden
Das Aktionsmenü des Schema-Editors bietet schnellen Zugriff auf mehrere nützliche Funktionen zum Verwalten, Exportieren und Freigeben semantischer Schemata.
Es kann über eine dedizierte Schaltfläche in der Hauptschnittstelle des Editors aufgerufen werden.
Hauptfunktionen
- Erstellen einer neuen Vorlage Sie können eine Basisvorlage erstellen, die eine einzelne Beispielklasse enthält: Person, mit Eigenschaften givenName und familyName. Dieses Basismodell kann verwendet werden für:
• Untersuchung der Struktur und Logik des Systems;
• Einfaches Hinzufügen neuer Klassen und Eigenschaften;
• Beginnen Sie mit der Definition eines benutzerdefinierten Schemas, z. B. eines semantischen Modells von „Person“ mit verwandten ontologischen Klassen. - Das derzeit verwendete Schema kann in verschiedenen Formaten heruntergeladen werden:
• Natives Format („as-is“), nützlich für die direkte Wiederverwendung im Schema-Editor;
• JSON-Format, geeignet für die Integration in externe Systeme oder die Weiterverarbeitung. - Aufteilung der Regelung
Es steht eine Option zum Kopieren des Schemas als URL zur Verfügung, die eine schnelle und einfache Freigabe mit anderen Benutzern oder Tools ermöglicht. Dieser Link zeigt eine persistente Darstellung des Schemas, das im selben Editor oder in kompatiblen Umgebungen geöffnet werden kann. - Öffnen des Schemas in einer entfernten Instanz
Das gleiche Schema kann in einer zuvor konfigurierten Remoteinstanz des Schema-Editors geöffnet werden (z.B. in einer Drittanbieteranwendung oder einer benutzerdefinierten Umgebung). Diese Funktion ist besonders nützlich in Kontexten, in denen der Editor in ein Managementsystem, ein Dokumentenportal oder eine dedizierte semantische Entwicklungsumgebung integriert ist.
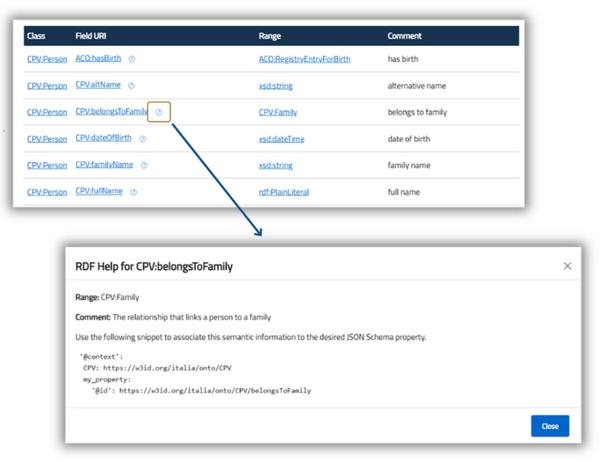
Konsultieren Sie RDF Helper
Der RDF Ontological Class Helper ist ein integriertes Werkzeug im Schema Editor, das Benutzer beim fortgeschrittenen semantischen Design von Schemas unterstützen soll.
Diese Funktion hilft, die RDF-Eigenschaften zu untersuchen, die mit einer bestimmten semantischen Klasse verbunden sind, was die korrekte Zuordnung von Eigenschaften erleichtert und die allgemeine semantische Qualität des Schemas verbessert.
- Das Tool führt automatisch eine SPARQL-Abfrage für die semantische Klasse aus, die im Feld x-jsonld-type des Schemas angegeben ist.
- Alle rdf:Eigenschaften, die der Klasse zugeordnet sind, werden abgerufen, mit nützlichen Details für jede Eigenschaft, einschließlich:
• rdfs:bereich: Gibt die Art des erwarteten Wertes an (z. Literal, URI usw.);
• rdfs:Kommentar: eine textliche Beschreibung der Immobilie;
• Anwendungsbeispiel: hilft zu verstehen, wie man die Immobilie richtig in das Schema integriert.
Die identifizierten Eigenschaften werden in ein interaktives Panel eingefügt, von dem aus der Benutzer sie analysieren und entscheiden kann, ob er sie in sein Modell integrieren möchte oder nicht.
Dieses Tool ist besonders nützlich, um die semantische Abdeckung des Schemas zu erweitern, eine ordnungsgemäße Anpassung an Standard-RDF-Vokabulare sicherzustellen, vorhandene Eigenschaften wiederzuverwenden, Redundanzen zu reduzieren und die semantische Interoperabilität zu fördern.